支持向量机的概念
边界问题
在逻辑回归模型中介绍了决策边界的概念,一个好的模型决策边界要将两个类别完全区分开,例如以下这些决策边界都是合理的:
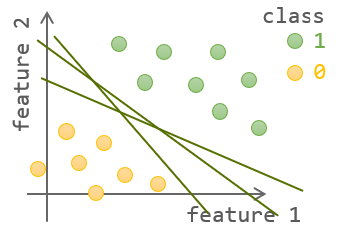
那么这就引出了一个问题,即如何在其中选择最佳的决策边界。在逻辑回归中,这条边界线的参数是通过求代价函数的最小值得到的。但直观上理解,一个好的决策边界应该离每个分类群体都尽可能远,这样在引入新的样本时不至于轻易地落到决策边界的另一边。
支持向量机(support vector machine)使用了一种边界(margin)最大化的思路来解决这个问题,具体来说就是确定这样一条决策边界线,使它到两个分类的距离最远,那么它应该落在两个分类最中间的位置,因此这样的决策边界可以很好地分隔开两个分类,就像这样:

支持向量机的参数确定
接下来介绍支持向量机的数学原理,这样可以明确模型到底需要求解什么。支持向量机的原理是让边界最大化,因此优化的最终目标就是求解最大的间距:
这就需要从距离的角度建立模型。在平面中,点到一条直线的距离可以使用公式 \\( \displaystyle{d=\frac{|Ax_0+By_0+C|}{\sqrt{A^2+B^2} }} \\) 计算。该公式可以推广到 3 维及更高维空间中,即点到 n 维度超平面的距离的计算公式为:
在 SVM 中,需要确定这样一个直线或平面 \\( \boldsymbol{w}^T\boldsymbol{x}+b=0 \\) ,使得它到两类样本的间距相同且最大,那么间距的计算公式为:
这里最小的意思是间距只取决于离决策边界最近点的计算结果。然后需要找出具有最大边界时的参数 \\( \boldsymbol{w}, b \\) ,那么就需要求解以下目标:
计算最小值时参数向量已经确定了,不影响最小值的计算结果,因此可以将其移到外面处理。因此 SVM 的优化目标为:
SVM的优化目标是如何得到的
为了明白 SVM 的优化目标为什么是这个,需要弄清到底在求什么。求解的目标就是最大间距,但是间距有两个约束条件:
- 所有样本都在间距外,即样本离决策边界最近的距离不小于间距
- 决策平面需要落在两类样本之间,能将两类样本区分开
因此有如下公式及约束条件:
\\[ \begin{align} & \underset{\boldsymbol{w}, b}{\mathrm{argmax}} \quad d \\ & \text{s.t.} \quad \frac{|\boldsymbol{w}^T\boldsymbol{x}_i+b|}{\|\boldsymbol{w}\|} \geq d > 0 \quad \text{and} \quad \begin{cases} \boldsymbol{w}^T\boldsymbol{x}_i+b > 0 \quad y_i = +1 \\ \boldsymbol{w}^T\boldsymbol{x}_i+b < 0 \quad y_i = -1 \end{cases} \end{align} \\]这里将两个分类记作 +1 和 -1,因为分类代表的数字只是一个记号而已,并且这样做可以将第二个约束条件改写为:
\\[ y_i(\boldsymbol{w}^T\boldsymbol{x}_i+b) > 0 \\]这样就可以将约束条件合并为一个:
\\[ \text{s.t.} \quad \frac{y_i(\boldsymbol{w}^T\boldsymbol{x}_i+b)}{\|\boldsymbol{w}\|} \geq d \\]如果令 \\( k=d \|\boldsymbol{w} \| \\) ,那么有:
\\[ \begin{align} & \underset{\boldsymbol{w}, b}{\mathrm{argmax}} \quad \frac{k}{\|\boldsymbol{w}\|} \\ & \text{s.t.} \quad y_i(\boldsymbol{w}^T\boldsymbol{x}_i+b) \geq k \end{align} \\]可以给参数 \\( \boldsymbol{w}, b \\) 同时乘上 \\( k \\) 从而消去该参数,这样就得到了以上的优化目标。而对参数 \\( \boldsymbol{w}, b \\) 的同步放缩并不会改变优化目标,因为放缩后 \\( \displaystyle{k\boldsymbol{w}^T\boldsymbol{x}_i+kb = 0} \\) 代表的是相同的决策边界,就像 \\( x+2y-3=0 \\) 和 \\( 2x+4y-6=0 \\) 代表的是同一条直线一样。
就像代价函数一样,一般来说都将最大值问题转换为最小值问题分析,因此最终的目标就是解决以下问题:
解决带约束的最值问题一般使用的方法是拉格朗日乘子法。在附录中列出几篇文章,里面有更详细的证明。
使用SVM
在 Scikit-Learn 中,支持向量机模型位于 svm 模块中:
SVC 即支持向量分类器(classifier),如果要让它产生线性的决策边界,需要指定参数 kernel 为 "linear" :
SVC(kernel='linear')
之后还会遇到非线性的决策边界。除了 SVC 外,Scikit-Learn 中还提供了 LinearSVC 类,它是专用于线性边界的支持向量分类器,并且带有正则化惩罚项,计算效率比 SVC(kernel="linear") 更快。
之前在介绍模型的原理时介绍过,间距是根据离决策边界最近的样本确定的,这些离决策边界最近的样本称为支持向量(support vectors),所有的支持向量决定了支持向量机所具有的参数。至此可以明白支持向量机的名称由来,这些支持向量一起支撑起了分隔超平面的参数向量。不管模型的样本有多少,只要支持向量不变,那么模型便不发生改变:
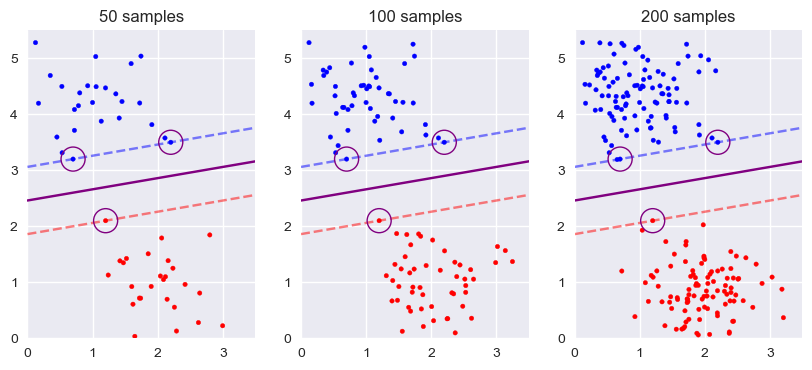
在 Scikit-Learn 中,可以通过 .support_vectors_ 参数得到建立模型的所有支持向量,或者通过 .support_ 参数得到支持向量在样本中的索引:
支持向量机的注意事项
支持向量机的原理较为简单,但在使用时也有一些问题需要注意。
数据标准化
支持向量机作为一种需要计算距离的模型,可能发生不同特征变量因为量纲级别相差过大导致的问题。为了更好地说明这个问题,以下是一个这样的示例:
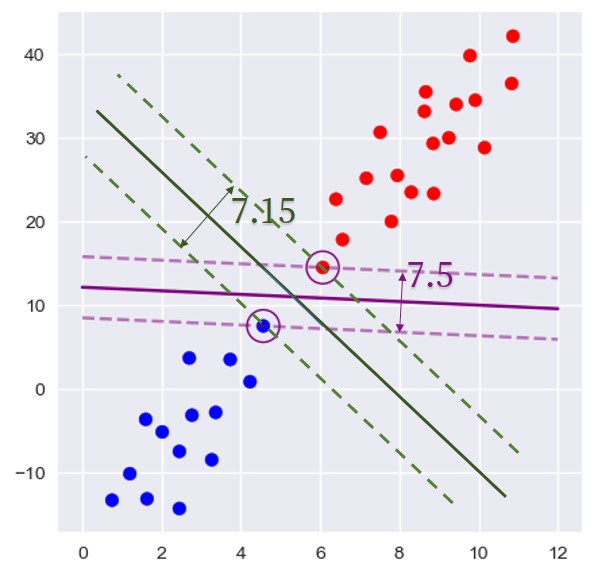
直观上看,深绿色的边界应该能更好地区分两组样本,但计算结果却显示紫色是最好的边界。这是由于纵坐标的量纲明显远大于横坐标的量纲,对距离的影响权重也更大。因此在使用 SVM 之前,需要做数据标准化处理,主要目的是使不同特征的量纲级别统一,计算距离时拥有相同的权重。
常用的数据标准化方法有以下两个:
- min-max 标准化
min-max 标准化也称离差标准化,它利用原始数据的最大值和最小值把原始数据转换到 \\( [0,1] \\) 区间内,具体的转换公式为:
其中 \\( \max \\) 和 \\( \min \\) 分别为原始数据的最大值和最小值。
- z-score 标准化
min-max 标准化处理方便,但有一个关键的缺点:如果数据中有远超正常数据取值范围的异常数据的话,那么会使得其它的正常数据被压缩在一个更小的区间内,反而不利于处理。z-score 标准化也称标准差标准化,通过原始数据的均值和标准差对数据执行标准化处理。
z-score 标准化后的数据符合标准正态分布,即均值为 0 ,标准差为 1 。它所使用的转换公式如下:
其中 \\( \text{mean} \\) 和 \\( \text{std} \\) 分别为原始数据的均值和标准差。
使用代码对数据做标准化处理的步骤与为数据添加多项式特征的步骤一致:( min-max 标准化也是一样的,只不过需要用到 MinMaxScaler 类)
经过标准化处理得到的数据可以被 SVM 更好地划分了:

软间隔
以上介绍的支持向量机要求两个类别能够被直线分开(线性可分),但有的时候样本未必能被直线完全分开,或者分开的效果并不好。
下图展示了两种这样的情况:左图中由于一个异常样本使得决策边界被大幅改变,而右图中的异常点使得根本不存在这样一个边界能将两类样本完美区分:
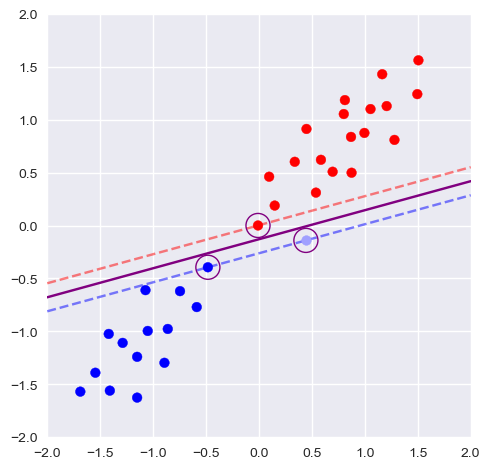
相比让间隔完全分开两个类别(硬间隔),适当允许一些样本存在间隔中甚至另一边可以缓解由异常值导致的问题。这种情况下,模型的间隔不再要求一定要硬性分隔两个类别,因此称为软间隔。
为了衡量一个样本与正常分类间隔的偏离程度,需要引入了松弛变量 \\( \xi \\) 。一个样本离它应在的区域越远,则对应的 \\( \xi \\) 也就越大:
引入松弛变量后,模型的参数需要重新确定,软间隔 SVM 的基本数学形式如下:
参数 \\( C \\) 用于控制模型的软硬程度:越大的 \\( C \\) 值会使模型的约束更大,\\( \xi_i \\) 也需要更小一些,样本不能超过间隔太多;若 \\( C \\) 为无穷大,则 \\( \xi_i \\) 只能无限接近于 0 ,样本只能在间隔的两边,此时 SVM 变回了硬间隔 SVM 。
在 Scikit-Learn 中,同名超参数 C 用于控制模型的软硬程度:

通过设置一定的 C 值,可以使模型更加灵活,避免异常数据带来的不利影响。
核化SVM
之前介绍的 SVM 都具有线性边界,但有些时候样本并不能用直线分开,例如:
即使将模型设置得足够软,使用直线也无法完全分开两个类别。这时,可以使用在逻辑回归中提及的方法,为模型添加上非线性特征项,例如多项式特征项:
此时模型的划分效果为:
添加非线性特征实现简单,但如果添加的特征较多,会在计算 \\( \boldsymbol{x}_i^\mathrm{T}\boldsymbol{x}_j \\)(参见附录 SVM 的求解)向量内积时速度变慢。
因此这种变换并不是任意的,通过特定的核函数(kernel function)可以在为数据添加许多特征后,并没有引入额外特征的计算。具体而言,就是找出这样的函数 \\( k(\boldsymbol{x}, \boldsymbol{y}) = \phi(\boldsymbol{x})^\mathrm{T}\phi(\boldsymbol{y}) \\) ,使得数据由 \\( \boldsymbol{x} \\) 变为 \\( \phi(\boldsymbol{x}) \\) 后,计算 \\( \phi(\boldsymbol{x})^\mathrm{T}\phi(\boldsymbol{y}) \\) 可以化简为计算 \\( \boldsymbol{x}^\mathrm{T}\boldsymbol{y} \\) ,从而使复杂度相同或相近。在使用时只需要定义具体的核函数,这样就不需要定义映射函数 \\( \phi(\boldsymbol{x}) \\) ,从而只需要计算变换后的向量内积,省去了变换过程的开销。
在之前的线性 SVM 中,使用参数 kernel="linear" 表示使用线性核函数 \\( k(\boldsymbol{x}, \boldsymbol{y}) = \boldsymbol{x}^\mathrm{T} \boldsymbol{y} \\) ,即不添加任何特征。线性核函数计算速度快,且还存在许多优化算法(例如 LinearSVC 使用的算法),是初次处理数据的首选算法。
除了线性核函数,对于之前的非线性数据可以使用多项式核函数 \\( k(\boldsymbol{x}, \boldsymbol{y}) = (\gamma\boldsymbol{x}^\mathrm{T} \boldsymbol{y} + c)^d \\) 。多项式核函数的特点是可以通过使用不同的 \\( d \\) 控制最高项的次数,从而控制特征映射的复杂度。但一般不建议使用过高的次数,因为这可能使核函数的结果太大或太小。
在 SVC 中,通过指定超参数 kernel 为 "poly" 可以使用多项式核函数。如果使用多项式核函数,通过超参数 degree 可以控制最高项的次数(默认为三次);通过超参数 gamma 可以控制同名系数;通过超参数 coef0 可以控制常数项。例如,以下是最高项次数为二次的多项式 SVC 分类边界:
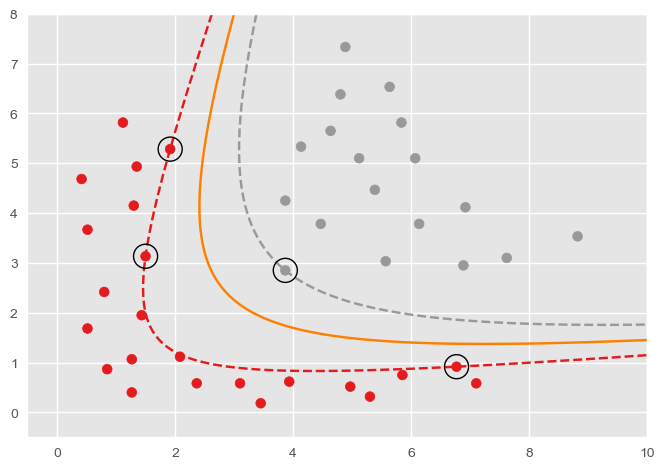
要注意的是,为数据引入非线性特征的目的并不是为了得到非线性的分隔面,因为点到曲面的距离难以求得。引入非线性特征的实质是将数据变换到高维空间中,使得变换后的数据在高维空间中线性可分。
为了更好地说明这个问题,接下来看一组示例数据:
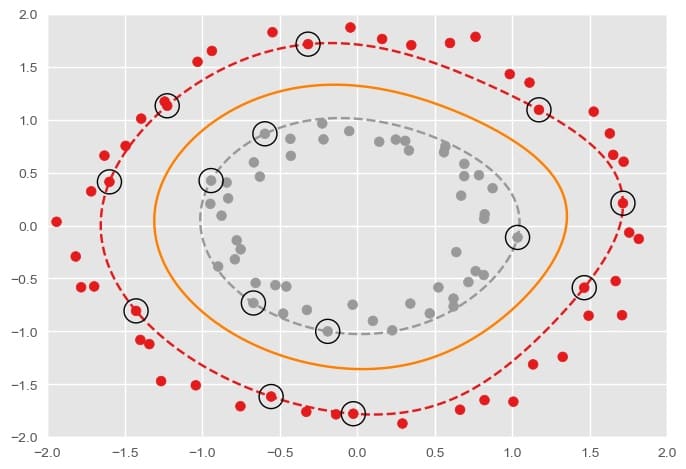
对于这样的数据,可以采用径向基函数核(Radial Basis Function, RBF,也称高斯核) \\( k(\boldsymbol{x}, \boldsymbol{y}) = \exp(-\gamma\|\boldsymbol{x}-\boldsymbol{y}\|^2) \\) 将其变换到高维空间。高斯核函数的特点是可以映射到无限维的空间中,因此具有很强的表示能力,但是相应的计算速度更慢,也更容易出现过拟合现象。
通过指定超参数 kernel 为 "rbf" 可以使用高斯核函数,这也是 SVC 默认采用的核函数。采用高斯核函数将原有数据映射到三维空间中,便可以在三维空间中看到数据可以由平面分隔开了:
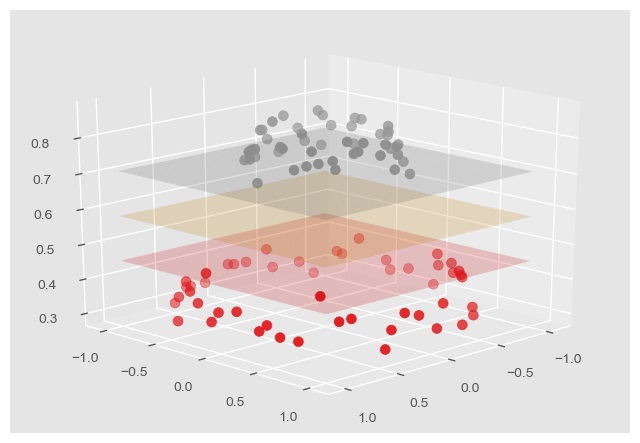
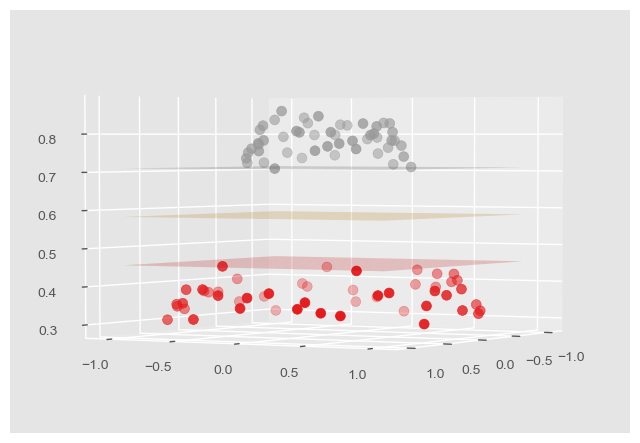
对于更高维的情况也是同理,因为实际数据的维度总是有限的,那么就肯定存在更高维的映射,使数据在更高维的空间中可以被超平面合理地分开。
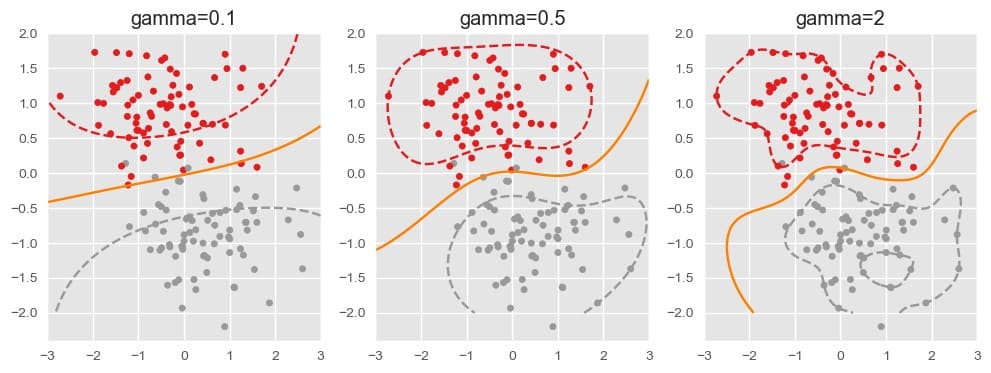
高斯核函数的另一个优点是可供调节的参数相比多项式核函数更少。唯一的参数 \\( \gamma \\) 用于控制高斯核的平滑程度:越大的 \\( \gamma \\) 将会使高斯核函数变化更剧烈,虽然能更好的拟合数据但会使过拟合风险增大。这对应于 SVC 的 gamma 参数,下图展示了不同参数取值情况下的分类边界:
支持向量回归
支持向量机不仅可以用作分类,还可以用于回归。在用作分类任务时,要求支持向量机规划一条最好的分类边界,使得它尽可能分开两类样本。而用作回归分析时,工作原理则相反:这时要求支持向量机规划一条最好的拟合边界,使得它尽可能包括所有的样本,就像这样:
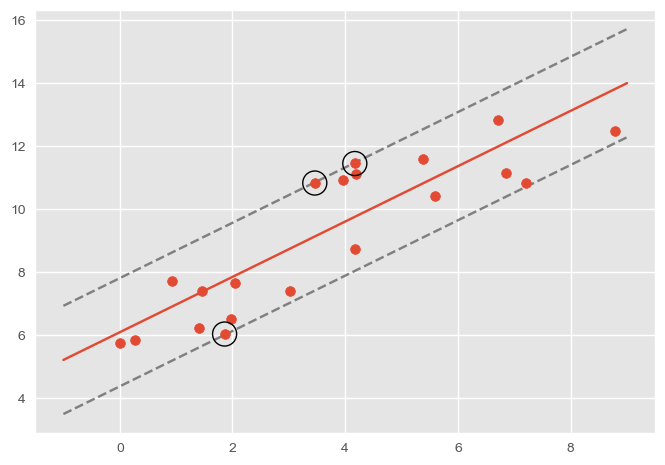
但通过包括所有样本来确定回归直线显然是不合理的,因为受到异常数据的影响很大。为了防止异常值的影响,要求边界不需要包含所有的样本,而是让所有样本都不要偏移边界内太多。
假设分隔面与两边界面的常数项相差 \\( \epsilon \\) ,那么一个样本与边界的偏离程度可以使用以下公式衡量:

如果样本位于边界以内,那么就不算偏离。总的代价函数每一个样本偏离程度的和,再包括正则项:
包含正则项后的 SVR 代价函数和 SVC 的代价函数较为相似,可以使用类似的方式求解。
在 Scikit-Learn 中,SVR 和 LinearSVR 是支持向量机的回归版本,后者针对线性模型做了额外的优化。从上文介绍中可以看出,它们有两个较为重要的超参数:
epsilon:分隔面与两边界的距离(实际上不是距离,而是常数项的差值)
由于落在两边界之内的样本不算偏离,对代价函数没有作用,因此 SVR 的支持向量是落在边界之外的样本,所有边界之外的样本才决定了边界的参数。参数 epsilon 可以看作模型对偏离数据的容忍程度,越大的参数值将会使边界内包含更偏离的数据,但这些不好的数据也会影响回归直线,使其对数据的拟合程度下降。
下图展示了不同 epsilon 取值下对数据的拟合程度:
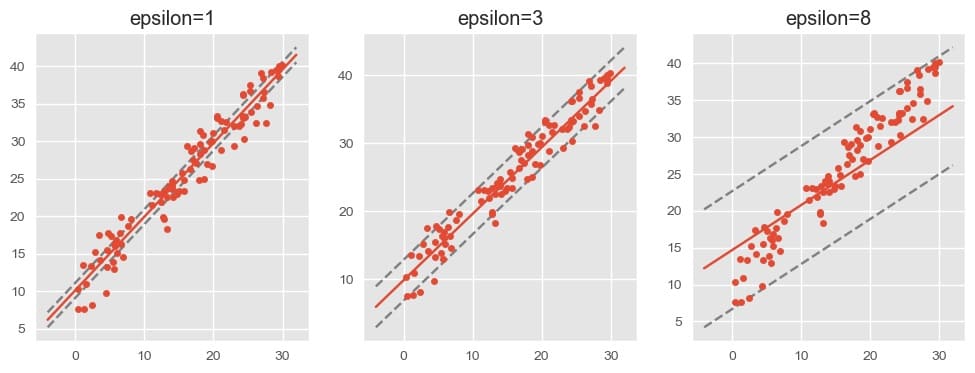
因此一般来说应选用尽量小的 epsilon 值。SVR 给出的默认值为 0.1 ;而 LinearSVR 给出的默认值为 0.0 ,这时所有数据的偏离程度都需要考虑,支持向量回归退化为和线型回归很相似的模型了。
C:模型的正则化强度。注意公式中的 \\( C \\) 不是正则项的系数,因此它的值越大正则化程度越低
下图展示了不同 C 取值下对数据的拟合程度:

取值过小时正则化太强,容易发生欠拟合;反之容易发生过拟合。
总的来说,支持向量机是一种可解释性强的分类模型,并可以用作回归。尽管没有用到统计方法,但它有严格的数学理论支撑,在实践中表现良好。支持向量机只取决于是它的少数支持向量,因此占用内存较少,预测新样本的速度也较快。核函数的引入使其不但可以处理各种类型的非线性数据,也可以很好地处理高维数据。
不过支持向量机也有训练时间长,对参数选择依赖较大等缺点,因此一般只在小批量样本上使用它。
附录
SVM求解
本节简单介绍 SVM 目标问题的求解方法。在参考文献中列出几篇文章,里面有更详细的证明。
首先回顾优化目标:
这是一个有约束条件的最值问题,一般使用拉格朗日乘子法处理这种问题,拉格朗日函数如下:
问题转换为求解 \\( \underset{\boldsymbol{w}, b}{\min} \underset{\lambda}{\max} L(\boldsymbol{w}, b, \lambda) \\) 。由于 SVM 满足 KKT 条件,因此它的对偶问题与原问题等价,也就是说可以交换里外的求最值顺序:
交换后内侧的最小值问题是对 \\( \boldsymbol{w}, b \\) 的无约束优化问题,可以通过令偏导为零的方式得到:
这时将求解 \\( \boldsymbol{w}, b \\) 的过程转换成与 \\( \lambda \\) 相关的问题,虽然没有得到 \\( b \\) 和 \\( \lambda \\) 的关系,但是可以将该等于作为约束项求解问题。
接下来将结果代入拉格朗日函数中,化简可得优化问题的最终形式:
得到最终结果后,只需将 \\( \boldsymbol{x} \\) 代入,即可得到有关 \\( \lambda_i \\) 的公式。要得到最大的结果,只需要对每个 \\( \lambda_i \\) 求偏导,并令结果等于 0 ,借助约束条件 \\( \displaystyle{\sum_{i=1}^{n} \lambda_i y_i = 0} \\) 就可以得到合适的 \\( \lambda_i \\) 值。从公式中也可以看出,主要的计算量在 \\( \boldsymbol{x}_i^\mathrm{T}\boldsymbol{x}_j \\) 上。
根据得到的 \\( \lambda_i \\) ,代入之前公式就可以计算 \\( \boldsymbol{w} \\) ,而再利用一个支持向量就可以计算参数 \\( b \\) 。
参考资料/延伸阅读
https://zhuanlan.zhihu.com/p/480302399
一份非常非常详细的 SVM 从零推导过程
https://zhuanlan.zhihu.com/p/24638007
一篇不错的关于 SVM 原理推导的文章



近期评论