XPath简介
XPath 是一种用作解析 XML 并提取所要信息的语法,就像 CSS 选择器一样。XPath 也可以用于解析其它类 XML 的文档结构,例如 HTML 。在本节中也主要以 HTML 为例演示 Path 的各种解析结果。
XPath 应用较为广泛,目前主流浏览器的开发者工具均支持使用 XPath 语法查找页面元素。XPath 解析速度较快,可以实现处理属性等许多 CSS 选择器无法实现的功能,但是语法较为复杂。
本节使用 Python 的第三方库 lxml ,该库提供了丰富的工具用于解析 XML 和 HTML ,其中就包括 XPath 。lxml 底层使用 libxml2 等 C 语言库实现,因此处理速度非常快。
lxml 可以使用 pip 安装:
解析 HTML 需要用到 lxml 中的 etree 模块:
使用 etree 模块中的函数 HTML() ,可以用来将一段 HTML 文本字符串解析为存储 HTML 结构信息的类:
该函数对 HTML 支持很好,甚至可以处理有一定破损的 HTML 。以上代码执行结果为:
可以使用该类的 .xpath() 方法来使用 XPath 语法解析。得到的结果是一个列表,包含解析得到的所有结果。
接下来正式介绍 XPath 的语法。
XPath语法
选取节点
HTML 等类 XML 文档都是使用树状的结构来表示文档。例如,对于以下简单的 HTML 文档:
那么它的所有元素构成的树状结构可以表示为:
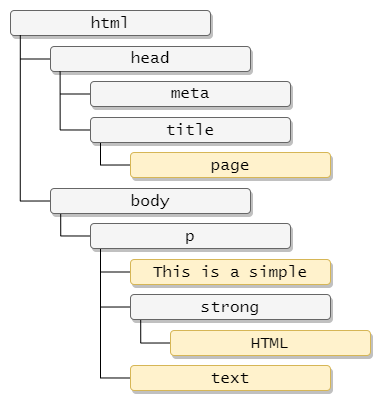
元素节点可以分为标签节点和文本节点。XPath 中通过一个斜杠 / 开头的标签名
来在文档树中向下匹配某一标签节点 tag 。通过堆叠这样的表示符号,即可表示若干节点的层级关系。
注意,使用该语法时必须要从根节点处开始搜索,例如:
使用单个斜杠只能表示相邻的层级关系,但如果使用两个斜杠:
就可以跨越表示相差任意深度的层级关系。因此以上匹配(在不引起歧义的话)也可以由下列形式表达:
也可以将其拆分理解,标签名表示一个具体的标签节点,而单个斜杠 / 表示两个节点的只能具有父子关系,而两个斜杠 // 表示两个节点具有祖孙关系,中间可以相差若干级。
除了使用具体的标签名外,还可以使用两个特殊的节点表示语法:
可以使用一个点
来代表当前节点,或使用两个点
来代表上一级节点。例如,以下可以搜索出与 img 标签同级的 figcaption 标签:
这种表示节点关系的语法很像 Unix 的文件路径。
在使用 lxml 处理文档的时候,很多时候都不能只使用一个 XPath 表达式就选中所有符合的元素,经常需要在处理到某一步后对结果做一些过滤后,再对符合条件的元素进一步处理。
每次调用 .xpath() 方法得到的都是一个列表,其中包含所有匹配的节点。可以在过滤后对其中的节点对象再次应用 .xpath() 方法,但此时注意需要表明“从当前节点开始匹配”,即不能以单个斜杠 / 开头。以下演示了错误的情况和几种正确的表示方法:
这种表示形式有点像 Unix 的相对路径表示,也是当前节点 . 常用的一种场合。
在实际应用中,相比搜寻节点更需要提取节点包含的文本信息。前面说过文本也可以看作一种节点,这种节点可以使用
代表一个标签元素内的文本内容。lxml 会将每一项包含的文本以字符串的形式放入返回的列表中。
在使用 text() 的时候要注意,元素包含的缩进及换行也算在元素的文本内。有些元素的部分文本放在它的子元素内,例如这种:
那么需要使用两个斜杠才能将这部分内容一并提取出来,并且提取出的结果被子元素分割了:
最后,总结一下本小节涉及的选取节点的基本路径符号:
| 表达式 | 描述 |
|---|---|
| tag | 标签名代表的某个具体的节点 |
| text() | 文本节点 |
| / | 所属的子节点;若用在开头,则表示位于根下一层的节点 |
| // | 所属的后代节点,可以是任意深度 |
| . | 当前节点 |
| .. | 当前节点的父节点 |
谓语
上面介绍了 XPath 选取节点的方法,但很多时候并不希望选取路径上的全部节点元素,而是只选取具有特定性质的元素。
XPath 中的谓语(predicate)用于限定查找符合特定条件的节点元素。谓语以
这样的方括号形式出现在标签名后面。方括号内可以加上具体的谓词。
一个简单的谓词为:
代表选择文档中从上至下匹配路径的第 n 个标签。例如,以下表达式可以提取文章中第一段的所有文本:
与之类似的谓词是
代表匹配到的最后一个元素。在介绍了 XPath 的运算符后,可以使用简单运算来得到第任意个元素。当然这一过程也可以交给 Python 处理,写成如下形式:
注意,尽管这两个谓词都只得到一个元素,但是该方法的返回结果仍然是一个列表。
标签名
也可以做谓词使用,代表选择匹配到的标签需要含有该子标签(只能是父子关系)。例如,以下提取包含链接的单元格文本:
更为常用的限定与属性相关。XPath 表示属性的符号为:
如果直接将属性作为谓词放入方括号中,那么代表标签需要存在该属性。更常用的做法是判断属性的值是否符合要求,那么这个时候就需要使用以下语法:
例如,通过 class 属性检索合适的节点是一种很常见的做法:
考虑到这是一种很常用的语法,因此这里提前介绍了一个关系运算符。
属性除了作为谓词,还可以直接用作节点,获取某个属性对应的值。例如获取链接对应的 URL :
这种情况和文本节点一样不可能再会有子节点和谓语,因此只会出现在最后。当然再对它们应用子节点和谓语也不会发生异常,只是结果可能未必符合预期。
谓语还常与通配符一起使用。在 XPath 中,通配符
可以表示任意标签节点,而通配符
可以表示任意属性节点。使用 id 属性寻找元素也是一种常用的做法,此时就可以配合通配符,例如:
注意这里同时使用了两个谓语串联限定,串联谓语也是从左向右顺序结合。如果想要表示所有的节点(包括标签节点、文本节点和属性节点),那么可以使用
来表示。
由于 HTML 是一种不够规范的标记语言,在编写属性的时候可能会出现多个属性值或有额外空白符。例如,对于以下文档片段:
在 CSS 选择器中,可以使用 pre.codeblock 来选中并修改所有代码块的样式。但是 XPath 的解析却很严谨,这会造成因为值没有完全匹配而忽略的情况:
此时可以使用以下谓词来处理这类标签:
只要节点 node 对应的值内含有 “ value ” 字符串,那么该标签就会被匹配。
这种节点可以是属性节点也可以是文本节点,例如对 class 属性的处理一般为:
类似地,也可以使用
作为谓词,来选取所有以特定字符串开头的属性值或文本内容。
最后总结一下涉及的语法。注意,所有谓词均可看作布尔值:
| 表达式 | 描述 |
|---|---|
谓词放在 node[] 的方括号内,表示限定 |
|
| node | 包含该类子节点 |
| n | 位于该位置 |
| last() | 位于最后一个位置 |
| contains(node, "value") | 节点值包含该字符串 |
| starts-with(node, "value") | 节点值以该字符串开头 |
| @attribute | 属性节点 |
| * | 任意标签节点 |
| @* | 任意属性节点 |
| node() | 任意节点 |
运算符
之前说到 XPath 的谓词可以看作布尔值,因此可以使用或、与、非做逻辑运算,通过多个条件获得需要匹配的标签。
逻辑运算“与”“或”“非”的关键字分别为:
or
not()
为了防止歧义,逻辑非需要像函数一样加上括号。以下是两个使用示例:
除了逻辑运算外,XPath 也有自身的运算符。这些运算符都作为谓语的一部分使用。
例如数学运算:
| 运算符 | 功能 | 运算符 | 功能 |
|---|---|---|---|
| + | 加法 | ceiling() | 向上取整 |
| - | 减法 | floor() | 向下取整 |
| * | 乘法 | mod | 取余 |
| div | 除法 |
例如,要选取倒数第二个列表项,可以使用:
再如,如果要选择中间项,可以使用:
除了算术运算符外,还可以使用以下关系运算符:
关系运算符常用在对纯 XML 文档的解析上,因为 XML 经常使用某个标签存储一个数值。不过关系运算符可以配合以下函数
该函数泛指位置,配合关系运算符就可以选取特定位置范围的标签,例如:
或者以下函数
用于统计符合条件的子节点个数,例如:
表达式组合应用得当可以处理很多关系,例如像 CSS 选择器的伪类一样选择偶数位置的节点:
以上涉及的表达式都用在谓语内,还可以使用符号
用在两个表达式内,表示对两个表达式匹配的元素取并集。例如,以下可以选取所有的链接:
轴
轴(Axes)是 XPath 中的一个更高级的概念。轴用于从文档树中定位和当前节点具有一定位置关系的那些节点,相比基本的 XPath 表达式可以表示更复杂的位置关系。
轴的使用通过以下语法表示:
其中 axisname 表示限定位置关系,node 表示限定该位置上的节点类型。这些位置关系可以有:
| 名称 | 效果 | 名称 | 效果 |
|---|---|---|---|
| ancestor | 选取所有祖先 | ancestor-or-self | 选取所有祖先及自身 |
| descendant | 选取所有后代 | descendant-or-self | 选取所有后代及自身 |
| following | 选取文档中位于其之后的所有节点 | following-sibling | 选取之后的所有兄弟节点 |
| preceding | 选取文档中位于其之前的所有节点 | preceding-sibling | 选取之前的所有兄弟节点 |
| child | 选取所有子节点 | attribute | 选取节点的所有属性 |
| parent | 选取所有父节点 | self | 选取当前节点 |
| namespace | 选取所有命名空间节点 |
例如,对于以下 HTML 结构:
如果想提取 #xpath-tutorial 的二级标题后的第一段,假设使用一般的同级节点表示方法:
那么没法定位到这样一个结果。而使用轴就可以很清楚地表示这种位置关系:
就像它的名称一样,轴是一种很强大的定位关系。
lxml的其余内容
其它XPath语法
前文说了在 lxml 中,通过 .xpath() 方法都会返回匹配节点组成的列表。然而 lxml 还支持这样的一些 XPath 语法,它们的返回结果是单个值。因此这些语法并不一定在浏览器的调试界面中能得出结果。
例如,当 count() 作用于一个表达式时,会返回包含的结果个数,并且在 lxml 中结果以浮点数形式给出:
再如,string-length() 可以返回一个文本的字符个数,并且结果可以被用在关系运算中:
还有一个比较好用的 local-name() 用于获取节点的标签名,有时在使用通配符时会用到:
XPath 还有许多类似这样的语法,不过并不是很常用,因此这里就不介绍了。
最后需要说明的是,本节的主要目的是为了介绍 XPath 语法,而不是介绍使用 lxml 处理 XML 文档的方法,因此可能涉及一些虽然很强大,但实际上并不直接使用的 XPath 语法。就像正则表达式不能表示所有的情况一样,XPath 尽管很强大,但也不是万能的,在适当的时候还是应该辅以编程语言的功能协助处理。例如提取一个元素包含标签、属性以及文本的所有结构,使用纯 XPath 比较难实现,但是 lxml 就提供了 Python 函数来处理这个问题:
此外,一昧地追求复杂的 XPath 表达式可能会让代码变得晦涩难懂,并不是一种合理的使用方式。
参考资料/延伸阅读
https://www.w3.org/TR/2017/REC-xpath-31-20170321/
XPath 3.1 标准
https://devhints.io/xpath
一份 XPath 语法小抄



近期评论