在上一节中,介绍了参数的概念,并用以下图片来表示传参的过程:
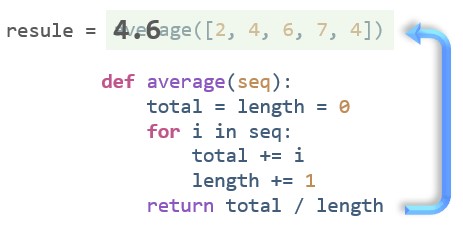
但是实际上,Python 的参数传递方式有很多,下面逐一介绍。
函数的多种参数
位置参数和关键字参数
一个函数可能有多个参数,在定义时需要将这些参数逐个声明在圆括号内:
...
在传入参数时,必须按照定义时的顺序将实际参数填入函数调用时的括号内,绝对不能过多或过少,否则就会引发错误。传入实际参数的顺序要和定义形式参数的顺序一致,不然形式参数就会接收到错误的值,可能会导致严重的后果。
考虑以下用于计算等差数列前 n 项和的函数,这里没有使用公式计算,而是使用了最原始的累加方式:
该函数定义了三个参数:首项 first 、公差 inc 、项数 n 。如果传入的参数过少,不能满足求和的条件,那么自然会导致错误;如果传入的参数过多,没有变量能够接纳它,也会导致错误;如果传入的参数顺序错误,那么它们被解释为错误的含义,计算得到的结果自然也会出问题。
这种直接按照顺序接收括号内填入的实际参数,必须和定义函数时的位置一一对应,就像最开始的那张图片展示的一样,称为位置参数。以下调用函数就使用位置参数的形式传参:
25
除此之外,还有一种称为关键字参数的传参方式。在使用关键字参数的形式传入参数的时候,形式参数使用等号被赋予实际参数的值,就像普通的变量赋值方式一样,如下:
以下是使用关键字参数向之前的函数传参:
26
使用关键字参数传递实际参数的优点在于,哪个参数接收哪个值在传参的时候便表现地一目了然,只需要关注参数的含义,不需要知道按什么顺序填入。因此这种方式可以不受参数位置的影响,在传参的时候可以任意调换参数的位置:
26
位置参数和关键字参数可以在调用时混用,但是必须要确保关键字参数在位置参数的后面,否则 Python 解释器无法确定位置参数表示哪个位置。
由于关键字参数比较好用,Python 中可以在定义一个函数时,使用星号 * 占据一个参数的位置,表示在此之后的参数都只接受关键字参数的传参形式,即按照如下形式定义参数:
...
那么 paramn 及其之后的参数都只接受 paramn=argn 形式的传参方式。如果不按照此规则传入参数,那么会发生错误。在此之前的参数则可以按任意形式传参。
Python3.8 新增了一种语法,可以使用斜杠 / 占据一个参数的位置,表示在此之前的参数都只接受位置参数的传参形式。
例如,对以下函数声明:
那么参数 a 和 b 都只能以位置参数的形式传入,参数 e 和 f 都只能以关键字参数的形式传入,而 c 和 d 则不受限制,可以按任意形式传入参数。因此,调用该函数时,前两个参数必定代表 a 和 b ,并且必定存在 e=... 和 f=... 的关键字参数。
如果查阅 Python 内置函数 divmod() 的帮助,可以看到:
Help on built-in function divmod in module builtins:
divmod(x, y, /)
Return the tuple (x//y, x%y). Invariant: div*y + mod == x.
这表明 divmod() 的两个参数都只支持按位置形式传参的方法。
可变参数
在 Python 中,通常使用 print 函数来打印变量。该函数可以一次性打印多个变量,多个变量的打印结果以空格隔开:
>>> v2 = 0.75
>>> v3 = [1, 2]
>>> v4 = sum
>>> print(v1, v2, v3, v4)
a 0.7 [1, 2] <built-in function sum>
仔细观察传参的过程,可以发现向 print 函数中传入了许多个位置参数。但是传入的参数个数是不确定的,可能为 4 个,也可能为 5 个、10 个 或 146 个。但函数在定义参数时,无法确定到底要定义几个参数,因为不管是位置参数还是关键字参数,都必须使定义的参数个数等于传入的参数个数。
如果需要让函数接收可变个数的参数,可以使用可变参数。可变参数在定义时,需要在参数名前面加上星号 * ,如下所示:
...
当然,参数也可以写作 *data 、*hello 等任意星号后接一个变量名的形式,这种情况下该变量代表的参数会被解释为可变参数。
接下来通过以下函数观察可变参数的实质:
可以这样调用该函数,给它传入任意数量的参数:
('str', 0.12, [6, False]) <class 'tuple'>
根据结果可以看到,可变参数实际上就是将许多参数封装成了一个元组,以元组的形式传入函数内部处理。
明白了这个道理以后,就可以编写类似以下的函数来处理可变参数:
注意到 data 就是元组以后,就可以调用 sum() 和 len() 这两个能接收元组作为参数的函数了。当然也可以使用 for 循环直接遍历它。
以上可变参数在传递参数时都是使用位置参数的形式,除此之外还有一种关键字形式的可变参数。关键字形式的可变参数在定义时,需要在参数名前面加上两个星号 ** ,如下所示:
...
同理参数也可以写作 **kw 、**options 等形式,总之这种情况下该变量代表的参数会被解释为关键字形式的可变参数。
类似地可以通过以下函数观察关键字可变参数的实质:
可以给它传入任意数量的关键字参数,注意参数名可以是任意的:
>>> func_with_kwargs(name='John', age=12, gender=MALE)
{'name': 'John', 'age': 12, 'gender': 0} <class 'dict'>
原来,关键字形式的可变参数实际上是被封装成了一个字典,键是形式参数名,值是实际参数值,传入函数内部处理。
有一点需要注意的是,在定义函数时,参数的定义顺序必须满足以下规则:
- 一个函数定义时,最多只能有一个位置形式的可变参数,也最多只能有一个关键字形式的可变参数
- 位置形式的可变参数后面可以定义普通形式的参数,并且如果后面有普通形式的参数,它必须以关键字形式的方式传递实际参数
- 关键字形式的可变参数必须是最后一个定义的参数
也就是说,在传递实际参数时,首先要让位置参数根据位置一一对应,多余的位置参数被位置形式的可变参数接收;然后要让关键字参数根据关键字一一对应,多余的关键字参数被关键字形式的可变参数接收。
使用默认参数,可以让函数在传入不同参数时,得到不同的结果。例如以下计算三角形的函数,如果传入两个参数,就将它们当做三角形的底和高;如果传入三个参数,就将它们当做三角形的三个边:
Python 内置类 range 的构造函数也使用了类似的方式:当传入一个参数时,它被当做范围的结束值,此时起始值默认为 0 ;当传入两个参数时,它们分别被当做范围的起始和结束值;当传入三个参数时,最后一个参数被当做步长。
Python 中还存在以下语法:在一个序列前加上星号 * ,它会被展开为一系列参数供函数调用,例如:
>>> print(*ls)
1 4 6 9
>>> func_with_args(*ls)
(1, 4, 6, 9) <class 'tuple'>
这种参数传递的方式,等价于使用 for 循环依次从序列中取值,然后逐一填入函数调用的括号中。
有位置形式的参数处理就有关键字形式的参数处理,在一个字典前加上两个星号 ** ,它会被展开为一系列键值对映射的关键字参数供函数调用,例如:
>>> info = {'type': 'text', 'length': 592523, 'create-at': localtime()}
>>> func_with_kwargs(**info)
{'type': 'text', 'length': 592523, 'create-at': time.struct_time(tm_year=2022, tm_mon=5, tm_mday=20, tm_hour=12, tm_min=27, tm_sec=40, tm_wday=4, tm_yday=140, tm_isdst=0)} <class 'dict'>
对比可变参数的定义,就可以很好地明白它们的关系:调用函数时在实际参数前置星号可以将序列或字典展开成一系列参数,定义函数时在形式参数前置星号可以将一系列参数收集成序列或字典。
可变参数还有一个非常好用的功能,*args 和 **kwargs 组合在一起可以接收任意形式的参数。例如,以下实现了一个 print_any() 函数,如果检查满足 print() 需要的参数,就将接收的所有参数传递给它;否则,传递给自定义的 log 函数:
例如,以下尝试调用该函数:
1 2 ['a', 'b']
>>> print_any(1, 2, ['a', 'b'], sep='--')
1--2--['a', 'b']
>>> print_any(1, 2, ['a', 'b'], level='DEBUG')
[DEBUG] 1 2 ['a', 'b']
这时通过将一个函数的可变参数传给另一个函数,只需修改最终调用函数时传入的参数,而无需修改定义时的参数。
默认参数
如果在调用函数时不向某些参数传递值,那么 Python 解释器就不知道参数的具体值,由此发送错误。
不过 Python 提供了一种语法,可以在定义函数时带上一个可选的参数,使得它在调用函数时可以不进行传参数操作。若未传入参数,它取得默认值;若传入参数,它取得传入的参数。这种形式的参数,称为默认参数。
定义默认参数只需要在定义普通参数时用等号给它一个默认值即可:
...
任何非可变参数都可以当做默认参数使用,只有一个限制:默认参数的定义必须要在非默认参数之后,否则在调用时无法判断该参数是被忽略了还是使用默认值。
在定义函数时,经常会添加一些额外的参数让函数处理更多功能。但是有时候部分参数又用不上,只希望它保持一个常用的值即可,这个时候就可以使用默认参数。
例如,以下使用了这样一个求加权平均值的函数。但是在一般情况下求平均值时,其权重全部相等且为 1 。此时,就可以使用默认参数:
如果参数的默认值较多,使用关键字形式的可变参数也可以代替默认参数。例如,在某些编写桌面应用的库中,生成一个组件具有很多选项,那么此时就可以先使用关键字形式的可变参数,到了函数内部再进一步判断有没有给定相应的选项。不过,一般情况下不建议滥用这种行为,因为关键字形式的可变参数仅凭函数定义的基本信息无法很快明白到底该传入什么样的参数。
默认参数在使用时,有一个非常容易遇到的陷阱,在介绍时不能不提。考虑以下函数:
该函数可以将两个序列中的值交错排列在同一个列表中并返回。可以给函数一个默认值让交错结果添加到默认列表后,不然就添加到一个空列表后。尝试调用该函数,可以看到结果是正常的:
>>> ls_2 = [2, 4, 6, 8, 10]
>>> make_staggered(ls_1, ls_2)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
如果自行提供一个列表,让结果补充在它后面,也是可以的:
[1, 3, 5, 7, 9, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
不过,再次忽略默认参数的结果可能出乎意料:
>>> ls_4 = [-1] * 4
>>> make_staggered(ls_3, ls_4)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, -1, 1, -1, 1, -1, 1, -1]
明明在调用时让默认值取空列表,但此时前面明显多了一部分没有涉及到的元素。仔细观察,这部分元素是在第一次调用时该函数得到的结果。
出现这部分结果的原因在于,函数在被 Python 解释器处理后,参数的默认值也会随即生成。如果自行指定一个其它值,那么生成的默认值就会被放在一旁;如果空缺出这个参数,那么默认值就会被用上。
默认值和函数一起,不管调用多少次,自始至终只生成一次。而上一节介绍了列表是可变对象,在调用函数是会改变它的内在结构。因此,这个改变在函数调用完毕后,就被保留了下来,并在下一次调用时影响结果。
因此,函数的默认参数应该避免为可变对象,否则被改变的可变对象就会干扰函数的默认值。如果真的要让默认参数是一个可变对象,也不能直接将可变对象放在参数列表中,应该做如下处理:
这样,如果空缺默认参数,它就会在函数运行时创建一个空列表。
不过,这种特性有时候也有用。在深拷贝一个对象时,为了避免直接或间接对自身的引用导致循环拷贝,在默认参数中使用一个字典保留在当前复制过程中已复制的对象。
为函数提供注释
函数的文档
当定义完成函数后,需要为其编写一份简短的说明,介绍函数的用途、参数和返回值的含义,帮助使用函数的人更快明白其用法。
Python 的 docstring 提供了一种原生的对函数文档的支持。在每一个函数的开头,在函数体前,都可以直接放置一个字符串,这个字符串也需要和下面的代码一样有缩进,它就代表对这个函数的说明。
以下给出了一个示例:
在使用内置函数 help() 查看一个函数的说明时,docstring 就会被打印出来协助说明函数的用途:
Help on function fibonacci in module __main__:
fibonacci(n)
Return a list containing the Fibonacci series up to n.
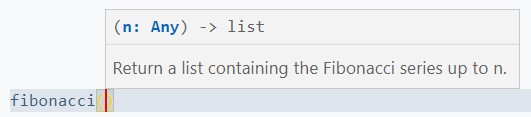
在使用编辑器或 IDE 编写代码时,一些专业的编辑器或 IDE 就会在调用函数时显示其文档,帮助使用者更好地明白如何应用该函数。
以下是在 Visual Studio Code 中的提示效果:
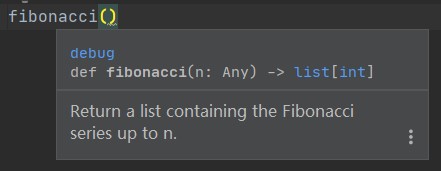
以下是在 Jetbrains Pycharm 中的提示效果:
当遇到一个不认识的函数时,可以通过检查其文档了解使用方法。以下是第三方库 sklearn 的帮助文档,可以看到它不仅提供了详尽的注释,还提供了使用示例:

类型注解
类型注解是 Python3 提供的一个实验性语法,用来表示一个参数的参数应该是什么类型的,以及它应该会返回什么类型的值。注意这里的表述“应该”,这里只是一种辅助性说明,Python 解释器并不会真正确定类型是否匹配。
类型注解在变量名后使用冒号 : 后面跟随一个具体的类型表明参数的类型,在参数列表的括号后、冒号前使用组合箭头符号 -> 表示返回值的类型,如下:
...
以下是一个使用示例:
类型注解有以下几个常用功能:
- 在
help()提供的帮助文档中,让使用者了解应该传入的参数类型 - 许多编辑器或 IDE 也会在使用时显示这些信息
- 一些第三方静态检查工具例如 mypy 可以根据类型注解对 Python 代码做静态类型检查
由于静态类型比动态类型的代码更易使用、更好维护,因此 Python 社区对引入静态类型的呼吁较高,许多 Python 项目都引入了类似的静态类型注解与检查功能。这里仅对类型注解做最基本的介绍,如果想了解更多有关于静态注解的资料,可以参考官方文档 https://docs.python.org/3/library/typing.html 。



近期评论