Pandas索引机制
pandas 相比 numpy ,一个很重要的特点就在于它引入了显式的索引机制。显式的索引在方便数据获取的同时,也可能造成学习上的困惑。接下来首先详细介绍 pandas 的索引机制。
Series与索引
之前说过,Series 对象可以看作一种字典,它提供了索引与值对的映射,因此可以使用字典一样的方式获取值:
Series 的许多操作都和 Python 字典很像,例如可以通过 item assignment 增加新的索引-值对,这等价于向 Series 添加新的一项:
这种自定义的索引是显式的,它是真实存在的,因此可以向字典一样获取所有的索引-值对:
Series 不仅有着和字典一样的索引操作,还具备和 numpy 数组一样的数组数据选择功能,例如数组索引:
这么看来,Series 的索引除了允许自定义外,和 ndarray 的索引好像没什么区别。不过注意,Series 的索引是允许重复的,这可能会导致一次性获取到多个值:
此外,这种索引在用作切片时,得到的结果将包含后端的值:
这样做的好处是不用明白它后一项的索引是什么。但如果索引有重复的话,将不能用于切片操作:
这种索引机制可能会导致数据获取的不便。但实际上,Series 依然保留了 numpy 数组从零开始、切片时前闭后开的隐式索引:
这两种索引方式很容易造成混淆,尤其是使用自定义整数作索引时,它可能会覆盖隐式索引,使得某些操作失效:
因此 pandas 提供了一些索引器作为取值的方法,它们是 Series 对象暴露取值与切片接口的属性。
第一种索引器是 .loc 属性,表示用的是自定义、可重复、类型不限、切片时包含两端的显式索引:
第二种索引器是 .iloc 属性,表示用的是从 0 开始、切片前闭后开的整数隐式(implicit)索引:
这两种索引器独立工作,不能混用,因此可以各自用于需要的场景中。
DataFrame与索引
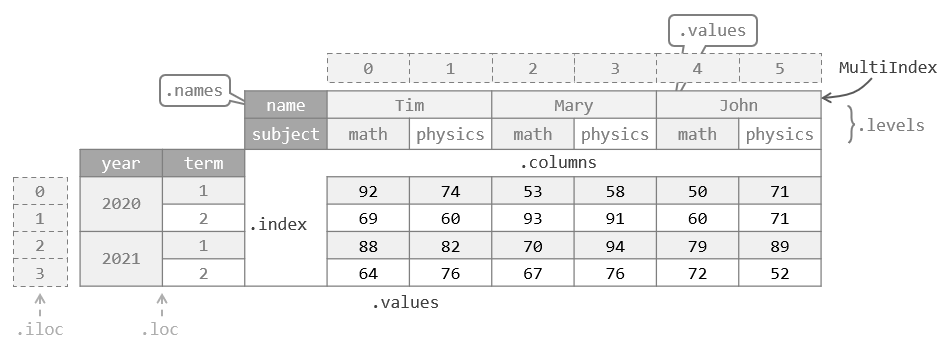
之前说过 DataFrame 也可以看作一种字典,它提供了列索引与 Series 对的映射,因此可以使用字典一样的方式由列索引获取一个 Series :
| units | unitcost | |
|---|---|---|
| pencil | 95 | 1.99 |
| binder | 30 | 19.99 |
| paperclip | 81 | 4.99 |
和前面介绍的 Series 对象一样,也可以用 item assignment 增加一列:
| units | unitcost | total | |
|---|---|---|---|
| pencil | 95 | 1.99 | 189.05 |
| binder | 30 | 19.99 | 599.70 |
| paperclip | 81 | 4.99 | 404.19 |
因此对列索引而言,它和 Series 的索引机制比较像。但是由于 DataFrame 行列都有索引,因此单级的显式索引只能作用于列,否则操作很容易引起歧义。
除此之外,直接对行或列应用隐式索引会引起错误。从概念上来说,对行和列的隐式索引容易存在误解:如果将 DataFrame 看作结构数组,那么一列就代表一个结构成员,列与列之间并没有严格的先后关系,直接取第几列这种操作无法让人明白其意图。而行虽然没有这种误解,但是会产生一个更关键的问题:直接取某一行使得行索引不再被用到而丢弃,返回一个 Series ,但是 Series 要求所有元素的类型一致,而一个结构各成员间往往有着各自各样的类型,强行统一它们的类型会造成类型提升,为后续操作带来更多问题。
一种特殊的情况是切片。切片将会保留行索引,得到的仍然是一个 DataFrame 。如果切片涉及的范围只有一行,那么就基本等价于获取 DataFrame 的某一行(虽然得到的仍然是一个二维数组):
| units | unitcost | total | |
|---|---|---|---|
| pencil | 95 | 1.99 | 189.05 |
因此,除了对列应用显式索引外,其它形式的索引不仅应该使用索引器,而且应该使用 numpy 高维数组的索引方式。
例如,以下使用隐式索引器获取 DataFrame 的元素。这里在代表取值的方括号内传入了一个元组,第一个元素指代行的隐式索引,第二个元素指代列的隐式索引:
根据隐式索引的规则,获取的应该是第 3 行第 2 列位置的元素。
再如,以下使用显式索引器得到指定几行的元素。这里对行应用数组索引,对列使用单个冒号 : 表示全部切片:
| units | unitcost | total | |
|---|---|---|---|
| pencil | 95 | 1.99 | 189.05 |
| paperclip | 81 | 4.99 | 404.19 |
最后,下图总结了 DataFrame 的索引:
层级索引
层级索引的概念
通过之前的介绍可以认识到,DataFrame 是一种二维的结构。但有些时候,处理的数据可能不止两个维度。例如,在操作 Excel 时,经常可以看到这样的表格:
| 2021 | 2022 | ||||
|---|---|---|---|---|---|
| mid term | end of term | mid term | end of term | ||
| grade 1 | class 1 | 86 | 88 | 89 | 90 |
| class 2 | 88 | 87 | 91 | 89 | |
| class 3 | 84 | 86 | 86 | 85 | |
| grade 2 | class 1 | 86 | 94 | 90 | 91 |
| class 2 | 85 | 84 | 87 | 91 | |
| class 3 | 87 | 91 | 90 | 90 | |
这种数据可以从四个维度聚合:对列来说,可以得出每个年度的得分平均值,也可以得出历年期中和期末的得分平均值;对行也是同理。只凭借二维数据无法实现这样的关系,这时就需要使用层级索引。层级索引可以从多个角度来描述数据的分组。
pandas 中的索引类型不仅限于数值和字符串,甚至还能使用元组,例如:
元组表示存储了多个值,是多级索引的基础。pandas 的 MultiIndex 类提供了更丰富的操作方法。可以用它的类方法从元组创建一个多级索引:
通过 names 参数可以为这两个层级指定名称,方面区分各索引层。层级名称会保存到索引对象的 .names 属性中。
如果将前面创建的 Series 对象使用 .reindex() 方法将它的索引重置为 MultiIndex 对象,就会看到一个层级索引结构:
关于层级索引,需要记住的是:层级索引可以看作一个元素对应多个索引,或者说一个索引元组。如果检查层级索引的 .values 属性,会发现每个索引都使用多个值来描述:
因此在获取元素的时候,也需要通过多个值,或者说一个元组来获取:
多个值或一个元组构成的索引也可以用于切片。除了索引由一个值变成一个元组外,均遵循一维 Series 的切片规则,例如可以使用显式索引器 .loc :
显式索引器使切片包含两端的元素。返回检查层级索引的 .values 属性可以发现,包含两端的元素确实是 3 个。
这里需要注意,如果层级索引不是有序的,那么大多数切片操作都会失败。以下演示一种会导致错误的操作:
问题出在切片和许多其它相似的操作都要求 MultiIndex 的各级索引是有序的。为此,pandas 提供了一些操作可以实现对索引的排序,最简单的方法是 .sort_index() :
经过索引排序后的切片结果就正常了。这里再次使用 inplace 参数来提醒默认情况下排序后得到的是一个新的对象,而不是在原有对象的基础上做修改。
层级索引相比普通的索引,索引类型由一个值变为多个值(或者说一个元组)。这看似多此一举,但是它允许从不同层面来处理一维的数据。如果访问层级索引的 .level 属性,可以得到:
这说明该层级索引有两层:从索引的角度看,第一层有 2 种不同的索引,第二层有 3 种不同的索引;从数据的角度看,根据第一层索引可以将数据分为 2 类,根据第二层可以将数据分为 3 类。因此数据在聚合、变换时,可以根据不同的索引层级,从不同的角度处理。例如,对于以上具有层级索引的 Series ,可以统计每个 "class" 的数值平均值:
新版本的 pandas 可能已经弃用了这种使用方式,或者抛出 FutureWarning ,提示说应该使用对表作分组计算后再合并,这就是以后介绍的内容了。
具有层级索引的 Series 很像一个 DataFrame 。事实上,使用对象的 .unstack() 方法可以将一个多级索引的 Series 转化为普通索引的 DataFrame :
| group | 1 | 2 | 3 | |
|---|---|---|---|---|
| class | ||||
| A | 1341 | 1412 | 1263 | |
| B | 643 | 632 | 685 |
或者使用 .stack() 方法实现相反的效果,将一个 DataFrame 变成具有多级索引的 Series 。 既然可以用含多级索引的一维 Series 数据表示二维数据,那么就可以用 Series 或 DataFrame 表示三维甚至更高维度的数据。借助多级索引,可以使三维及以上的数据以一种较为易读的形式表示出来。层级索引每增加一层,就表示数据增加一维,使得 DataFrame 可以表示任意维度的数据。因此 pandas 并没有提供三维及以上的数量类型。
DataFrame与层级索引
在 DataFrame 使用层级索引和在 Series 上使用层级索引是一致的,只不过列索引和行索引都可以设置为层级索引。
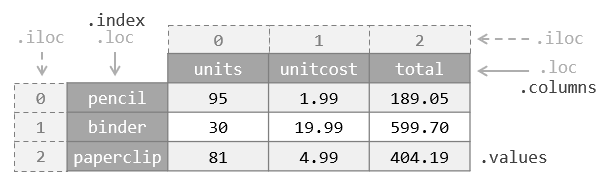
以下创建一个较为复杂的、行列都具有两级索引的 DataFrame 用于演示:
| name | Tim | Mary | John | ||||
|---|---|---|---|---|---|---|---|
| subject | math | physics | math | physics | math | physics | |
| year | term | ||||||
| 2020 | 1 | 92 | 74 | 53 | 58 | 50 | 71 |
| 2 | 69 | 60 | 93 | 91 | 60 | 71 | |
| 2021 | 1 | 88 | 82 | 70 | 94 | 79 | 89 |
| 2 | 64 | 76 | 67 | 76 | 72 | 52 | |
对 DataFrame 索引和 Series 基本一致,需要通过元组形式的索引来获取一个 Series ,并会保留行的层级索引:
索引器和切片的用法都是一致的:
| name | John | Mary | ||
|---|---|---|---|---|
| subject | math | math | ||
| year | term | |||
| 2020 | 1 | 50 | 53 | |
| 2 | 60 | 93 |
不过这种索引元组的用法不是很方便,因为这个 DataFrame 实际上可以看作四维数据,但是只能在两个维度上切片。如果想获取所有人在第 1 学期的数学成绩,那么可能需要这样的索引:
这是错误的用法,它会直接导致解释出错。为此,pandas 提供了 IndexSlice 对象,专门用来解决高维 DataFrame 的切片问题,例如:
| name | Tim | Mary | John | |
|---|---|---|---|---|
| subject | math | math | math | |
| year | term | |||
| 2020 | 1 | 92 | 53 | 50 |
| 2021 | 1 | 88 | 70 | 79 |
下图总结了 DataFrame 的层级索引: