数组的统计
有时要获取数组的某些统计值,例如最值、总和、方差等。这种统计值可以使用 numpy 相关的函数来获取:
相比 Python 内置的相同作用的函数,numpy 对数组操作做了一些底层的优化,计算会更快一些:
下表列出了 numpy 提供的统计函数:
| 函数名称 | 描述 | 函数名称 | 描述 |
|---|---|---|---|
| sum() | 计算元素的和 | min() | 得到最小值 |
| prod() | 计算元素的积 | max() | 得到最大值 |
| mean() | 计算元素的平均值 | argmin() | 得到最小值的索引 |
| average() | 计算元素的加权平均值 | argmax() | 得到最大值的索引 |
| median() | 计算元素的中位数 | ptp() | 计算元素的最值之差 |
| std() | 计算元素的标准差 | percentile() | 计算元素的百分比位数 |
| var() | 计算元素的方差 | any() | 验证是否存在元素为真 |
| all() | 验证所有元素是否都为真 |
除了 any() 和 all() 外,这些函数都有一个以 nan 开头、对 NaN 值的安全处理版本,在计算时忽略所有的缺失值。
对于这些聚合函数,一种更简洁的形式是对数组对象直接调用对应的方法:
any() 和 all() 是比较特殊的聚合函数,因为它们只针对布尔数组。配合上一节介绍的通用函数,可以快速检查数组是否符合某一条件。例如,可以使用以下代码来检查数组中是否有值为 10 的元素:
numpy 提供的统计函数还允许操作多维数组时,沿着某一个维度聚合。例如,对于一个二维数组,可以对某一行或某一列聚合:
下图展示了数组“在 axis=1 上聚合”的原理:
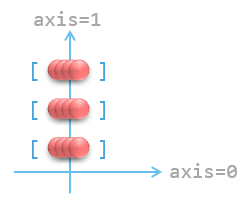
注意,聚合得到的结果比原数组低 1 个维度。
数组的排序
numpy 的 sort() 函数可以实现数组的高效排序。sort() 函数返回的是原始数组的副本:
如果希望用排序好的数组替代原始数组,可以使用数组的 .sort() 方法。
另一个相关的函数是 argsort() ,该函数返回的是原始数组排序完成的索引值:
这些索引值可以用作索引数组,来得到这个数组有序的视图:
使用 numpy 的排序函数可以通过 axis 参数,沿着某个维度排序。例如:
对单一数组排序可能会遇到几个相同的值。可以综合多个数组使用 lexsort() 函数排序,该排序得到的结果也是索引数组:
partition() 函数可以用于找到数组中 K 个最小值。该函数得到的结果是一个新数组,最左边是 K 个最小值,往右是任意顺序的其他值:
类似的也有一个 argpartition() 函数,不过返回的结果是索引。