Python 中的函数大体可分为以下两类:
- 标量函数:作用于单个值,并返回单个值,例如 abs()、pow() 、divmod() 以及整个 math 模块中的函数都是标量函数。
- 集合函数:作用于一个集合或序列
标量函数比较简单,这里就不再做额外的介绍。集合函数根据作用的效果,又可以细分为以下三类。
- 映射:函数将运算作用于集合的每个元素,作为结果返回的集合与输入集合长度相同
- 过滤:函数将判断作用于集合的每个元素,以此舍弃一部分元素,返回的集合是输入集合的子集
- 归约:函数将集合内元素汇聚在一起,生成单个值作为结果,也称为累积
这三种类型的函数在 Python 中都有典型的代表,下面先介绍这几个典型代表。
典型高阶函数:map、filter和reduce
map:映射
标量函数将数值从定义域映射到值域。例如 math.sqrt() 函数做的标量映射就为将一个浮点数 x 映射为另一个浮点数 y ,它们满足映射关系 \\( y \Leftarrow \sqrt{x} \\) 。
map() 是一个 Python 内置的集合映射函数,它接收一个函数和若干个列表(或者其他能够用 for 循环遍历的对象),并通过函数依次作用在列表的每个元素上,得到一个新的列表并返回。例如:
不过该函数的返回结果比较让人疑惑,它提醒得到了一个“map对象”,却不告诉具体包含了哪一些值。
这是因为 map() 得到的结果是一个可迭代对象。关于可迭代对象,这里暂时不做介绍,只需要知道它不是序列,因此直接打印它不会像序列一样可以直接观察其包含的每一个元素。
在以后介绍到 Python 的面向对象编程时,将会详细介绍可迭代对象的概念和实质。
后续会介绍 Python 中的生成器,从生成器的角度就可以明白可迭代对象的作用了。不过目前只需要明白以下两点就可以了:
- 可迭代对象可以使用
list()等转化为一个序列 - 可迭代对象可以使用
for循环依次取出其包含的每一个值
因此,可迭代对象有序列的特征。将其转换为列表,就可以很清楚地观察到结果了:
map() 的作用原理,可以用下图很清晰地表示出来:
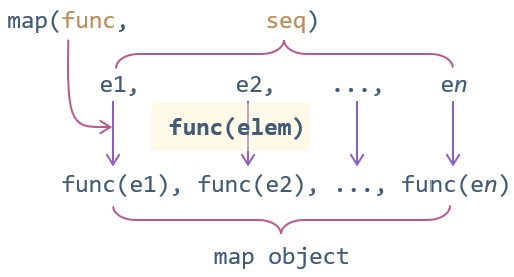
map() 将函数作用于序列中的每一个元素,并得到作用后的结果,因此表示一种映射关系。map 在英文中也有映射的意思。
lambda 匿名函数特别适合作为 map() 所需要的函数,因为它只需要在传参的过程中用一下,然后就丢弃了。
例如,以下实现了这样一个集合映射:将集合中每一个为偶数的元素的值变为其一半,非偶数的元素的值变为其平方:
结果为:
map() 函数也可以作用于多个可迭代对象,这种情况下其传入的函数会依次接收每一个可迭代对象中的元素作为参数,由多个参数得到一个结果。
以下示例,使用一个列表中的元素作为底数,另一个列表中的元素作为指数,使用映射关系得到每一组元素的幂:
如果不同序列长度不一样,那么结果的长度会被截断,只执行到可以映射一部分:
filter:过滤
filter() 函数的作用是把一个测试函数应用于集合中的每个值。如果测试结果为真,则保留该值,否则将其舍弃,最终根据结果得到一个子集。
以下给出了一个简单的示例,将一个整数列表中所有奇数剔除:
注意 filter() 函数得到的结果也是一个可迭代对象,需要将其转换为列表才能观察包含的内容。
下图表示了 filter() 函数的作用原理:
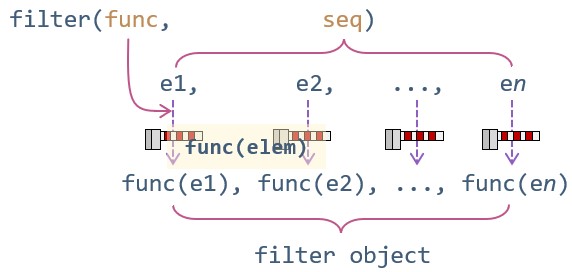
filter() 函数就像一个闸门,测试函数是闸门的控制杆,它决定了每个元素是否可以通过测试。
reduce:归约
相比前两个函数,reduce() 的作用可能稍微难理解。该函数不是 Python 内置函数,它存在于标准库中,需要提前将其导入进来:
reduce() 传入的函数必须接收两个参数,reduce() 对可迭代对象中的每两个相邻元素反复调用传入的函数并得到一个结果,并返回最终生成的结果值。
下图表示了 reduce() 函数的作用原理:
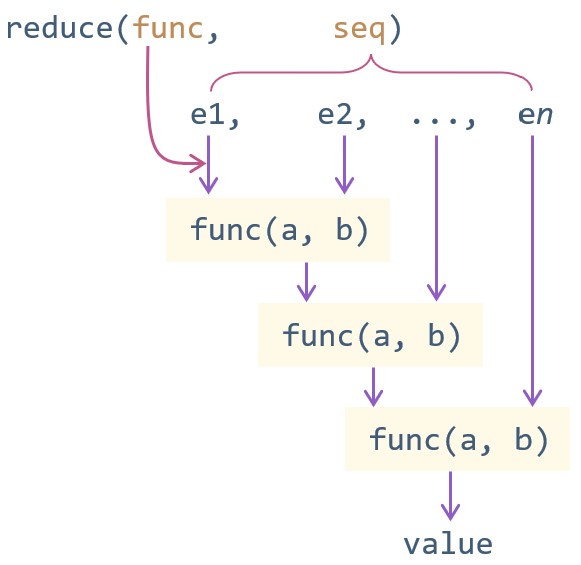
注意,reduce() 函数是返回一个具体的值,而不是可迭代对象。可以看出 \\( reduce(f, [x_1, x_2, x_3, x_4, \dots ]) \\) 等价于 \\( f( \dots (f(f(x_1, x_2), x_3), x_4) \dots ) \\) 这种形式。
下面通过两个具体的示例来介绍该函数的用法。更高级的用法在介绍了 functools 的其余实用函数后再介绍。
从一个高维列表中找出某一个元素,则需要若干次取值操作,每次取值都取出一个高维列表中的某一个子列表,从而将维度降低一级,若干次降维之后即可得到零维的元素。如果将以上行为翻译成reduce() 操作,则可以表示为对一个列表执行取值操作,再对得到子列表再次重复这一操作直至结束。相应的代码可以表示为:
如果不熟悉第三方库 NumPy 也不要紧,只需要知道它将 100 到 104-1 的所有数值按顺序重新排列成了一个 4 维的数组,每个维度的数组都具有 10 个元素。如果对传入的函数不太理解,可以改写成 lambda arr, n: arr[n] 这种直接的取值形式。以上函数的执行结果为:
这与直接逐个取值的结果是一样的:
如果要对一个列表内的元素逐个相乘,并得到累积结果,这一过程可以表示为:对列表内每两个相邻元素相乘,将得到的结果再与下一个元素相乘。那么,用代码就可以表示为:
其它常用内置函数
接下来介绍一些常用的内置函数。由于它们已经被细分好了用途,因此它们并不都是高阶函数。同时,这些函数按照特点,都可以使用 map() 、filter() 和 reduce() 表示。
映射函数
reverse:反序映射
反转序列是一种比较常用到的操作。使用 reversed() 函数可以快速反转序列。
以下给出了一个简单的示例:
从结果中可以看到 reversed() 就像 map() 和 filter() 一样,不会立即得到结果,需要显式将结果转化为序列。
reversed() 函数不能用于可迭代对象,只能用于序列。也就是说,map() 和 filter() 等函数的返回结果不能使用该函数反转值的顺序。
也可以使用切片 [::-1] 实现反序,但是切片会立即得到结果,有时候无法满足要求。
enumerate:包含索引值映射
enumerate() 函数将输入序列的每一个元素扩展为一个二元组,其中第一个元素是索引值,另一个是原始输入元素。使用该函数可以为序列或者可迭代对象添加索引值信息。
以下给出了一个简单的示例:
enumerate() 函数有一个非常常用的情景就是既需要用到一个序列的元素,又需要用到一个元素的索引值,此时就完全可以用它来取代
i, sequence[i]
...
这种别扭的形式。因此,enumerate() 函数常用在循环中,写作:
...
以下给出了这样一个示例函数,用于从一个序列中寻找一个元素:如果找到,它返回元素的索引值;否则,返回空值 None :
归约函数
all和any:布尔规约
all() 函数用于判断一个集合内的所有元素是否都为真:如果都为真,它也返回真 True ;如果有一个不为真,它就返回假 False 。
它等价于以下函数:
any() 函数用于判断一个集合内的所有元素是否存在真值:只要有一个真,它就返回真 True ;如果没有真值,它就返回假 False 。
它等价于以下函数:
从它们的描述上可以看到,它们都是归约函数,将一个集合的元素归约成单个布尔值 True 或 False 。all() 函数对集合中的所有元素使用 and 归约,相当于在各个值之间加上 and 运算符。any() 函数使用 or 归约,相当于加上 or 运算符。
这两个函数与数理逻辑密切相关,all() 等效于全称量词 \\( \forall \\) ,其运算可以表现为如下公式:
由数理逻辑上的概念,可以研究一个有趣的命题:对一个空序列调用以上函数,即 all([]) 的结果如何?该命题可以把对空集的归约和对非空集的归约放在一起做交集来解决。
首先研究对空集和非空集的归约做逻辑与运算:
使用集合的分配律,可以将两个结果的与运算符改为两个集合做并集运算的形式:
注意到 \\( \emptyset \cup s \\) 就等价于 \\( \emptyset \cup s \\) ,也就是说对空集和非空集的归约做逻辑与运算的结果和空集无关,由此可以得出结论:对空集的 all 归约为布尔值真 True(真和另一值的与运算都取决于另一值)。
同理,any() 等效于存在量词 \\( \exists \\) ,研究方法与以上类似,不过要对空集和非空集的归约做逻辑或运算,这样才满足集合的分配律,可以让两个归约取并集。得到的逻辑或运算的结果仍然和空集无关,对空集的 any 归约为布尔值真 False(假和另一值的或运算都取决于另一值)。
可以验证 Python 的行为满足以上规则:
这是 all() 和 any() 函数初看可能比较违反直觉的一点。不过仔细查看两者的等价函数,可以发现其实现实际上是满足该规则的。
len和sum:汇聚归约
len() 函数用于计算序列中所有值的个数,即序列的长度。sum() 函数用于计算所有值的总数,即对序列的所有元素求和。
这两个函数在数学上意义相近:len() 函数把序列中每个元素看作 1(取 0 次方),然后返回所有元素的和;sum() 函数则把序列中每个元素看作实际值(取 1 次方),然后返回所有元素的和。
但在 Python 中的实现方法却有很大差别:sum() 函数可用于任何可迭代对象,len() 函数不能用于可迭代对象,只能用于序列。
这种实现方法上的不对等可能会导致在某些情况下遇到类型错误,因此注意在编写相关代码时为了扩展使用场景,需要在用到 len() 之前将参数转换为序列对象,例如:
zip:结构化和平铺序列
zip() 函数将来自多个集合的数据交叉组合在一起,将 n 个带有元素的集合转换为 n 元组。例如:
注:原文表述有误,不知道是不是翻译的锅
以上示例用 zip() 函数将两个集合的数据组合在一起,生成了一个二元组序列。并且可以看到 zip() 同样不会立即得到结果,需要显式将结果转化为序列。
如果只给 zip() 函数传入一个集合,那么得到的结果是只有一个元素的元组,这也符合逻辑。
对于归约函数,都需要知道归约空序列(即传入一个空序列作为参数)的结果,即归约时的单位元是什么。例如对于上文提到的几个函数,any() 的单位元是布尔值 False ,sum() 的单位元是数值 0 。可以通过代码检查 zip() 的单位元:
结果表明 zip() 的单位元是无数据,并且可以被转换为一个空序列。
zip() 有几个很常见的应用场景,例如,从两个序列构造成一个字典,此时就可以使用 zip() 将一个键值对合在一起:
zip 在英文中也表示拉链,可以认为该函数像拉链一样将两个序列并排缝合在了一起。
可以将其推广到更一般的应用场景。假设有许多个序列,它们在相同位置处表达的是同一个结构在同一维度上的信息,例如:
如果要处理各个结构的信息,那么一种朴素的方法就是使用 for 循环依次按索引值来处理每个元素:
使用 zip() 函数,可以将不同维度的信息按索引值组成一个整体,然后在遍历时可以按整体代替索引值,这样处理逻辑更清晰:
不过,zip() 函数使用时有一点需要注意:如果不同序列长度不一样,那么它们会被截断以保证长度相同:
这个特性有时也会造成一定的困扰。不过 Python 的标准库提供了一种替代的解决方案,这点留到后续介绍。
高阶函数
max与min:寻找最值
max() 函数和 min() 函数就像表明上的含义一样,用来寻找最大值或最小值的。这两个函数可以接收可变个输入参数,找出其中的最值;也可以接收一个集合,寻找其中的最值。例如:
注意,这两个函数默认情况下没有单位元,因为传入空序列是会发生错误的。不过它们都有一个关键字形式的默认参数 default ,用于表示当传入空序列时默认返回的值:
当 max() 函数和 min() 函数接收一个集合时,它们可以用作高阶函数,它的关键字参数 key 可以传入一个函数,该函数指定如何从集合中的每一个对象获取需要比较的值。
例如,给定以下包含元组的序列:
每个元组中,最后一个元素代表分数。如果要找出列表中分数的最大值,可以这样设计 key 的函数:
key 代表的函数需要是标量函数(作用于一个值,返回一个值)。
以下再给出一个示例,可以获取一个序列中绝对值最大的元素:
sorted:数据排序
sorted() 函数用于将数据排序。以下给出了一个简单示例:
该函数不同于以上介绍的其它函数,它会直接返回列表对象。也可以使用列表对象的 .sort() 方法将列表排序,但是使用 sorted() 函数的优点在于它不会改动原有列表,而是返回一个新列表,因此该函数是无副作用的。
该函数可以将任意可迭代对象排序,返回的结果都是列表。它和 max() 函数一样都有参数 key ,与列表的 .sort() 方法一样都有参数 reversed 用于指定是否降序排列。
参考资料
https://docs.python.org/3/library/functions.html
Python3 官方文档关于内置函数的介绍