数组的变形
数组常用属性
上一节介绍了 numpy 创建数组的方式。numpy 中的数组是一个 ndarray 对象,它提供了高效的存储与操作的方式,适合处理大量数据。
每个数组有 .nidm(数组的维度)、.shape(数组每个维度的大小)和 .size(数组的总大小)属性:
其它常用的属性包括表示每个数组元素字节大小的 .itemsize ,以及表示数组总字节大小的属性 .nbytes :
一般来说,可以认为 .nbytes 跟 .itemsize 和 .size 的乘积大小相等。
数组变形
变形是一种实用的操作,通过变形可以产生有一定规则,但难以直接创建的数组。
下表总结了常用的变形函数或方法,接下来会详细介绍:
| 函数 | 作用 | 返回结果 |
|---|---|---|
.reshape(shape, order='C') |
用数组现有元素重组变形 | 视图 |
.resize(new_shape) |
用数组现有元素重组变形 | 原始数组 |
.T |
转置 | 视图 |
.transpose(axes=None) |
高维转置 | 视图 |
.flatten(order='C') |
碾平为一维数组 | 副本 |
.ravel(order='C') |
碾平为一维数组 | 视图 |
.squeeze(axis=None) |
合并元素个数为 1 的维度 | 视图 |
.swapaxes(axis1, axis2) |
交换数轴 | 视图 |
数组变形最灵活的实现方式是通过 .reshape() 方法实现。例如,以下通过变形将数字 0~9 放入一个 3×3 的矩阵中:
注意,原始数组的大小(元素个数)必须要和变形后数组的大小一致。可以使用负数来自动计算某一维度的元素个数:
如果转换后形状无法兼容,则会产生 ValueError 异常。
该方法不会修改原有数组。如果想修改原有数组,可以调用 .resize() ,或者直接通过修改 .shape 属性实现:
.T 属性用于转置原有数组:
或者可以使用 .transpose(axes=None) 方法,该方法的优点是可以转置更高维的矩阵:
注意,两种转置返回的结果都是数组的视图(view)而不是副本。视图是原有数组中的部分元素重新按一定规律输出的结果,对视图内的元素做修改也会实时更新到原有数组内:
.reshape() 方法返回的也是数组的视图,因为它只涉及部分元素的重新排布。这种方式在处理大量数据时运行会更快,并可以减少副本占用的缓存空间。
有关数组的索引与切片将在下一节介绍。
变形与维度转换
有时要对数组的维度做变换,此时就会涉及数组的变形。使用 .flatten(order='C') 可以将高维数组碾平为一维数组:
该方法不会修改原有数组,返回的是原有数组的副本。
.ravel(order='C') 也用于碾平数组,不过返回结果是数组的视图。
.squeeze(axis=None) 用于将元素个数为 1 的维度并入其它维度中,即去除 .shape 属性中值为 1 的维度:
.swapaxes(axis1, axis2) 用于交换数值的两个维度。对于一个高维数组来说,最内层的数组的 axis 被记为 0 ,次外层为 1 ,以此类推:
该操作返回视图。交换最直观的反应就是 .shape 对应位置的值被互换了。
数组的拼接和拆分
以上所有的操作都是针对单一数组的,但有时也需要将多个数组合并为一个,或者将一个数组分裂为多个。
数组的拼接
下表列出了拼接或连接数组常用的方法:
| 函数 | 效果 |
|---|---|
concatenate(arrays, axis=0) |
拼接多个数组 |
append(arr, values, axis=None) |
拼接两个数组,未指定维度则碾平后拼接 |
vstack(arrays) 、row_stack(arrays) |
垂直拼接多个数组,即将数组的行之间拼接 |
hstack(arrays) 、column_stack(arrays) |
水平拼接多个数组,即将数组的列之间拼接 |
dstack(arrays) |
沿第三个维度,即高度方向拼接多个数组 |
stack(arrays, axis=0) |
拼接多个数组,且拼接完之后会变高一维 |
concatenate() 将数组元组或数组列表作为第一个参数,例如:
该函数也可以一次性拼接多个数组,或用于二维数组的拼接。
对于多维数组,有时还需要向别的方向拼接。在了解如何拼接前,需要进一步认识 numpy 的坐标轴。最外层的元素(维度 1 )的轴记为 0 ,它们包含的数组(维度 2 )轴记为 1 ,这些数组包含的数组(维度 3 )记为 2 ,以此类推:
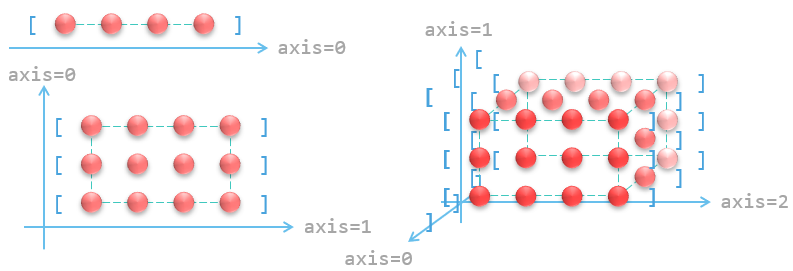
可以通过 axis 参数指定拼接的轴。下图展示了“在 axis=1 轴上拼接”的原理:
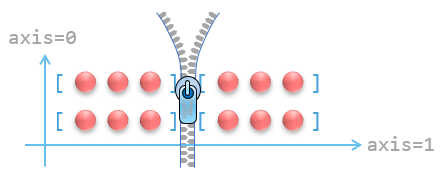
此时最内层的数组之间被拼接,示例如下:
append() 函数用于拼接两个数组,如果不指定 axis 会先调用 .ravel() 碾平(不改变原数组)再拼接,因此可用于拼接不同形状的数组:
拼接完成之后再将其修改为需要的形状即可。
沿着固定维度处理数组时,使用 vstack() 函数进行垂直拼接,或使用 hstack() 函数进行水平拼接会更加方便:
这两个函数还分别有别名 row_stack() 和 column_stack() ,从名字上也可以看出来它们分别用于拼接行和列。
与此类似,dstack() 函数用于将三维数组沿着高度作拼接。
stack() 有时也用于拼接数组,其特点是拼接得到的结果必定比原数组高一个维度:
数组的拆分
与拼接过程相反的是分裂。分裂主要通过以下函数来实现:
| 函数 | 效果 |
|---|---|
split(arr, indices_or_sections, axis) |
分裂成多个数组 |
hsplit(arr, indices_or_sections) |
沿水平方向分裂,即分裂数组的列 |
vsplit(arr, indices_or_sections) |
沿垂直方向分裂,即分裂数组的行 |
dsplit(arr, indices_or_sections) |
沿第三个维度分裂,即分裂数组的高 |
可以向以上函数传递一个索引列表作为参数,索引列表记录的是分裂点的位置:
每遇到对应位置便会拆出一个新数组,因此 N 个分裂点会得到 N+1 个子数组。
高维数组的分裂可以使用 axis 参数指定分裂的维度,例如:
下图指出了“在 axis=1 轴上分裂”的原理:
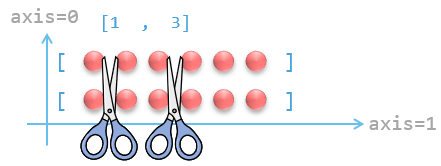
相关的 hsplit() 和 vsplit() 的用法也类似:
同样,dsplit() 函数将沿着第三个维度分裂。



近期评论