类的继承
什么是继承
在 Python 中,有些时候会遇到一个已经写好的类,这个类实现了一些基本的功能、方法,但是并不完善。例如,假设要编写一个游戏,在游戏中实现了怪物类 Monster ,它具有一些基本的属性和交互逻辑:
通过实例化该类,就可以往合适的位置添加一些怪物,并且每只怪物都可以拥有独立的攻击力等属性。
然而,游戏中往往存在许多类型的怪物,同类怪物还可以细分为许多不同的形态,如果要为每一种怪物都从头编写一个类,考虑到这些基础的属性及方法的定义都不会改变,就必须将这些重复的代码片段复制过来,就像:
这很明显是一种低效的方法:一个实现了基本功能的类可能有上百行代码,如果将所有代码复制过来,显然不方便调整和修改,容易产生疏漏,而且一旦游戏的底层逻辑被更新(例如增加了护甲这一概念),那么要为涉及的所有类重写方法,显然非常不合适。
在面向对象编程中,继承(inheritance)机制经常用于创建和现有类功能类似的新类,又或是新类只需要在现有类基础上添加一些成员(属性和方法),此时可以不用直接复制代码,而是通过继承获取被继承类拥有的属性与方法,从而轻松实现类的复用。
在 Python 中,定义类的时候如果在类名称后面加上一个小括号,里面传入需要继承的类名,表示这个类是继承基于已定义的类的:
...
这里的 DerivedType 是继承自 BaseType ,它拥有 BaseType 的所有属性和方法。被继承的类称为父类或超类,继承得到的对象称为子类(subclass)。在明确父类的定义后,子类通过继承获得的所有属性与方法实现均与父类相同。
由于子类继承的方法实际上是对父类方法的引用,因此当父类方法更新时,子类的调用结果也会随之改变。
对于上述类 Monster ,可以通过继承它来创建一个新的类,例如:
子类无需额外编写包括初始化在内的所有方法,就可以直接使用父类提供的属性操作,不仅省时省力,还降低了出现疏漏的可能。
继承与面向对象
面向对象编程思想的最终目的就包括使程序灵活性、重用性和可扩展性得以提升,而类的继承便很好地满足了该目的。
继承使子类可以拥有父类所有的属性和方法,在实际应用时,往往会提前写好一些具有基本功能的基类,在使用时要做的就是继承它们,然后添加上合适的业务功能,使开发效率可以大幅提升。
例如,以下是第三方库 SQLAlchemy 的使用示例。SQLAlchemy 用于处理 SQL 数据库,它已经提前编写好了数据表操作的基类,通过继承该基类,可以创建一个自定义的数据表:
继承得到的类只需要考虑数据表具有什么样的字段,而无需知道如何与数据库交互。在合适的时候,基类的方法会被调用,自动执行数据的更新或查找等操作,而无需考虑这些方法到底如何实现。
当有一个现有的、功能已经相当完善的类时,有些时候为了扩展这些类的功能,也会继承它并定义一些新方法,这样可以在保留原有类的优点时丰富它的功能。Python 标准库中的类都是很好的继承对象。
以字典类为例,可以基于它实现一个自己的字典:
对于这一个继承的字典类,它保留了字典的所有性质,并可以通过方法 .sort_value() 对值进行排序。它完全可以像字典一样使用:
子类也可以被继承,类可以这样无限继承下去,每继承一次,它的功能就更丰富了一层。
事实上,在 Python3 中定义一个类时,如果没有明确类是继承自哪一个类的,那么这个类便自动继承自内置类 object 。object 是 Python 类的基础,它实现了一些最基本的方法例如分配资源、名称表示等,可以说任何定义的类最终都是它的子类。
方法重写也是面向对象编程常用的一种手段。尽管有一些类已经实现了某个方法,但为了适应不同的业务逻辑,有时也需要重写父类提供的方法。
例如,以下是第三方库 Scrapy 的一个简单示例,通过继承 scrapy.Spider 基类,可以创建一个网络爬虫类。该类已经写好了完整了爬虫处理过程并在合适的时候调用相应的方法,而用户要做的就是重写关键的方法来适应当前爬虫业务。例如替换要爬取的网站等关键信息,以及重写 .parse() 方法来处理数据的解析流程:
重写之后该方法就可以替换原有流程的数据解析部分,而执行请求、解析数据等方法可以让父类提供,也可以通过重写实现自己的要求。
继承和重写使类的设计更模块化,在编写类的时候可以将整个过程拆解为一个个的方法,如果需要修改过程中的某一步,只需要继承该类并重写对应的方法,只要方法的参数和返回值等符合上下文调用的需求,即可简洁、清晰地做局部调整。
继承和重写也符合面向对象编程中多态的概念,即当多个类继承某一个类时,如果这些类都重写了某些方法,那么对不同的类调用相同的方法,就可以得到不同的结果。例如对以上的爬虫类,对不同的爬虫调用 .parse() 方法,解析数据的方式也不尽相同。
在 Python 中,继承还有一个很典型的应用场景就是异常。通过继承异常类型,可以逐步缩减异常涉及的范围,从而易于通过 except 语句捕获不同异常。
多继承
在 Python 中,一个类可以继承自多个类,只需要在代表继承的括号中输入多个类名:
...
这个新的子类就会保留继承的所有父类的属性和方法,同时兼具继承的所有类的特性。
对于多个父类中包含同名的类属性与方法,Python 会根据子类继承时圆括号中父类的前后次序决定,括号中排在前面的属性与方法会覆盖后面的同名属性与方法。
在使用多继承时,往往将其中一部分类用作接口。接口类定义了这些类中需要具有什么特性,也就是说需要拥有什么属性与方法。
在继承时,可以编写一种特殊的抽象基类。抽象基类不具有实际含义,不能被实例化,仅用于在继承时提示被继承的类具有什么特性,这种抽象基类往往被用于接口。collections.abc 模块提供了基础的抽象基类,继承该模块的抽象基类提示该类应该实现某些方法来实现特殊操作。
例如,以下的 Directory 类继承自 Path 类,提示它拥有路径的一些操作(例如切换目录、计算相对路径等),同时它还继承自 Iterable 类,这说明该类应该实现了某些方法,从而变成一个可迭代对象,
可以使用 for 循环从该类中迭代每一个成员(例如目录中的每一个文件或子目录)。关于可迭代对象的概念将会在后续介绍。
继承与super类
为什么要使用super类
前文中介绍了多继承,多继承允许一个类使用所有父类的属性与方法。然而这样做有一个很严重的问题:那就是父类之间的方法或属性标识符可能会冲突,从而相互之间发生覆盖造成一定问题。
考虑以下简单示例:
这两个类在单独编写或继承时,并没有什么问题。但是在多继承时,便会产生问题了:
两个类的初始化方法发生了覆盖,造成同名变量的赋值也被覆盖,这种覆盖是十分危险的。由于初始化方法需要为实例准备一些必要的属性,如果缺失这一步会造成缺少方法需要的资源,从而产生错误。
一种更复杂的继承情况涉及单继承和多继承的结合,这种情况下,多次调用同一方法也可能造成一定问题。例如,考虑以下继承关系:
这种继承关系如下所示,箭头之间构成了一个菱形,因此有时也称为菱形继承:
在菱形继承中,各种类方法之间复杂地纠缠在一起,稍不注意就可能产生混乱的调用问题。在以上示例中,尝试调用 D 类的方法:
从中可以看出,调用两个父类的方法时都各自调用了一遍 A 类的方法。当继承关系进一步变复杂时,调用还会更加混乱。
这种时候,可以使用 Python 内置的 super 类。
使用super类
super(type, object_or_type) 将得到一个父类或同级类的代理对象(proxy object),用于访问已在类中重写的继承方法。
其中,参数 type 是一个类名,而 object_or_type 必须是一个该类或该类的子类的实例化对象。
如果用在在类的实例方法内部,super() 函数的两个参数是可以省略的。这种情况下该类代表父类,可以用该类得到的实例来调用父类的方法,例如:
那么此时如果调用 B().m() ,通过 super 类就可以调用父类的方法,在控制台中打印提示文本。
在这个最简单的使用场景中,super 类充当了对父类的一个隐式引用,通过它来调用父类的方法。当然也可以直接使用父类调用父类的方法,不过采用 super 类含义更加明确,也更不容易出现疏漏。
在许多继承场合中,都需要额外调用父类的初始化方法来准备一些必要的属性,例如 Python 用于编写简易用户界面的标准库 tkinter 中,如果想继承一个控件类实现自己的控件,就需要调用这些类的初始化方法,为界面绘制提供参数:
当然也可以直接通过父类调用初始化方法 tk.Frame.__init__(self, master) 。
super类与多继承
以上对 super 类的应用似乎可有可无。解决多继承问题才是该类提出的根本目的。
在介绍 super 类处理多继承前,需要先了解 Python 的 MRO 。MRO(Method Resolution Order, 方法解析顺序)是 Python 中定义类的继承顺序的依据,用来处理多继承时的继承顺序。
在创建一个类时,Python 都会自动为该类创建一个 .__mro__ 属性,这个属性就是 Python 的 MRO 机制生成的。可以通过类的 .__mro__ 属性或类的 .mro() 方法来查看上面菱形继承的 D 类的 __mro__ 属性值:
.mro() 方法除了返回的结果是列表而不是元组外,结果是相同的。
目前 Python3 采用 C3 算法来获取类的 MRO 信息,该算法的细节可以在 https://www.python.org/download/releases/2.3/mro/ 查询到,这里对此做简要介绍,仅供了解所用。
如下是一个复杂的继承关系,箭头指向父类,并且先继承的类位于左侧:
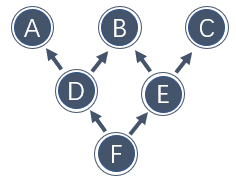
当要生成 F 的继承顺序时,C3 算法过程如下:首先将被指向箭头数量为 0 的节点(没有被继承的类)F 放入 MRO 列表,并将这些节点及与有关箭头从继承树中删除;接下来继续找相似特征的节点,此时如果同时找到符合条件的类,则取左侧优先放入 MRO 列表并从树中删除下一步查找满足的节点有 A 和 E ,根据左侧优先取出 A ,按如此顺序得到的 MRO 为
F,D,A,E,B,C。不过注意,Python 所有类都有一个共同的父类object,因此最后会将object放入列表末尾。最终生成列表中元素顺序为:
F→D→A→E→B→C→object。感兴趣的话可以编写代码验证。
当用 super 调用父类的方法时,会按照 __mro__ 属性中的元素顺序逐个查找方法,object_or_type 对应的类负责确定 __mro__ 属性,而 type 参数在 __mro__ 中寻找上一个类作为父类。
如果不是很理解这个表述,请看以下复杂继承的示例:
以上代码一共得到了 5 种不同的代理对象,它们的指代分别为:
尽管 A 类看起来与 E 类没有任何关系,但是代表的却是 E 类的实例。回顾一下这种继承关系得到的 MRO 顺序:
结果便不言而喻了。记住 type 参数确定的父类的是 object_or_type 参数在 MRO 中指向的后一个类。
之前说过
super()的第二个参数也可以是一个类,不过这是对于调用类方法而言的。有关类方法的内容将会在下一节介绍
回到之前提出的第二个问题,如果采用 super 类来调用父类方法:
那么就不会出现重复调用的情况了:
任意复杂的继承情况,每一个类在 MRO 中只会出现一次,因此这样避免了方法的重复调用,使得复杂的继承也不容易出错。
参考资料/延伸阅读
https://docs.python.org/3/tutorial/classes.html#inheritance
Python3 官方文档对继承的介绍,不过这部分比较简洁
https://docs.python.org/3/library/functions.html#super
Python3 官方文档对内置函数 super 的介绍



近期评论